Customer Churn Prediction
Customer churn prediction for a SaaS business

Skills Used



Challenge
My initial goal was to build a single model to predict customer churn across the board. However, the project presented significant challenges related to data complexity and customer behavior heterogeneity. Defining churn required establishing a specific time window (90 days post-cutoff) and carefully handling event data like cancellation dates and support tickets to create an accurate target variable. The primary technical hurdle emerged during exploratory analysis, which revealed vastly different churn rates and patterns between newly acquired customers (<90 days tenure) and established ones. This necessitated a strategic pivot from a single-model approach to developing separate analyses for these distinct segments. Furthermore, engineering meaningful predictive features from raw interaction data (billing cycles, support contact frequency/recency) proved complex and iterative. While feature engineering yielded results for established customers, creating features with predictive power for the critical early churn phase using only signup-time and initial usage data turned out to be a major obstacle, indicating limitations in the available data for that specific segment.
Results
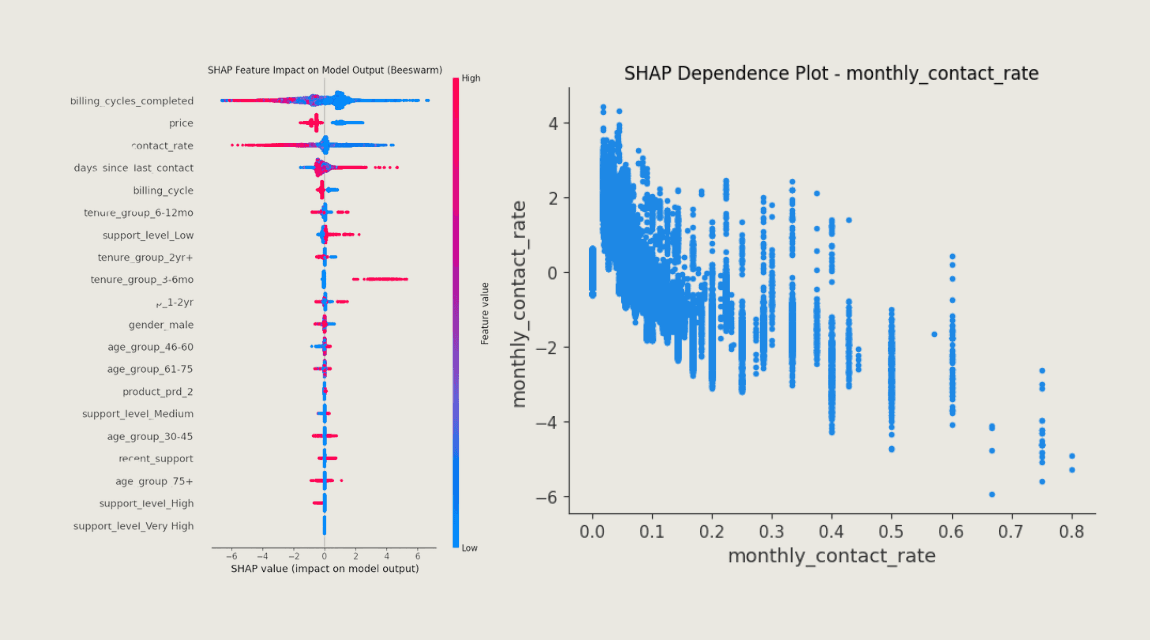
The primary achievement was the development and optimization of a high-performing XGBoost model specifically for established customers (>90 days tenure). This model demonstrated high precision (0.95) and strong AUC scores (ROC: 0.83, PRC: 0.51), making it highly effective for identifying likely churners within this group for targeted retention efforts while minimizing disruption to loyal customers. The process provided deep insights into the drivers of churn for established customers through SHAP analysis, revealing factors like billing frequency, tenure length, and support interaction patterns that significantly impact retention. This offers actionable intelligence beyond just prediction. Perhaps most importantly, the difficulty in modeling new customer churn highlighted the critical need for different data sources (potentially related to acquisition channels or onboarding experience) to address this specific business problem effectively. This project significantly enhanced my skills in advanced feature engineering, customer segmentation, hyperparameter tuning (RandomizedSearchCV), and model interpretation techniques (SHAP), preparing me for complex, real-world data science scenarios where understanding nuances in data and adapting the approach are key.